Before You Trust an AI with Your Money, Test It
I did not know how to pick an AI model for a finance use case. So I tried to build something to find out. I am still not sure I measured the right things.
In my last post I said I would share the results of the evaluation harness once I had them. Including where the models surprised me. And where the harness itself turned out to be the problem rather than the models. That is what this post is.
I want to be upfront about something before we get into it. I am not an ML engineer. I did not come into this knowing how to evaluate a language model. I read a few things, made some guesses about what mattered, and built a small tool to test those guesses. What follows is an honest account of what I tried, what I found, and how uncertain I still am about most of it.
The question I started with was simple. If I wanted to build a personal finance assistant using an open-source language model, how would I decide which model to use?
The benchmark sites were not much help. They measure things like reasoning and coding ability on standardised tests. That tells you something about a model's general capability. It does not tell you whether a model will correctly calculate a savings rate, return JSON when asked for it, or ignore a hidden instruction buried in transaction data.
So I tried to build something that would test those specific things.
The tool runs three open-source models (Llama 3.2 1B, Llama 3.1 8B, and Qwen 2.5 7B) through a fixed set of finance questions and scores each one across five dimensions. The models were chosen because they were available on the Hugging Face free tier, not because I had any particular reason to think they were the right ones.

The five things I decided to measure were accuracy, format adherence, latency, cost, and prompt injection resistance. I picked these because they seemed like things that would matter in a real application. I could easily be wrong about that. There are probably dimensions I missed entirely.
Here is what I thought each metric would tell me, and the assumptions baked into each one.
Accuracy: can the model do basic financial arithmetic correctly. I wrote four test questions with known answers. Four prompts is not very many. Whether that is enough to say anything meaningful about a model's accuracy, I genuinely do not know.
Format adherence: does the model return structured data when asked. Finance applications often need JSON or tables rather than prose. If it cannot do this reliably, the application breaks. This one feels like a more solid test than accuracy, because the evaluation is binary. Either the JSON parses or it does not.
Latency: how long does the user wait. I measured end-to-end response time across three query types. The thresholds I set (under 3 seconds for a simple query) felt reasonable but I made them up.
Cost: what does it cost at scale. I estimated this from token counts projected to 1,000 queries per month. The cost model is simplified and the projection is rough.
Prompt injection resistance: what happens when someone hides a malicious instruction inside what looks like transaction data. This is the one I feel most uncertain about. I tested five basic attack patterns. A more determined attempt would look very different.
Here is what the first run produced.
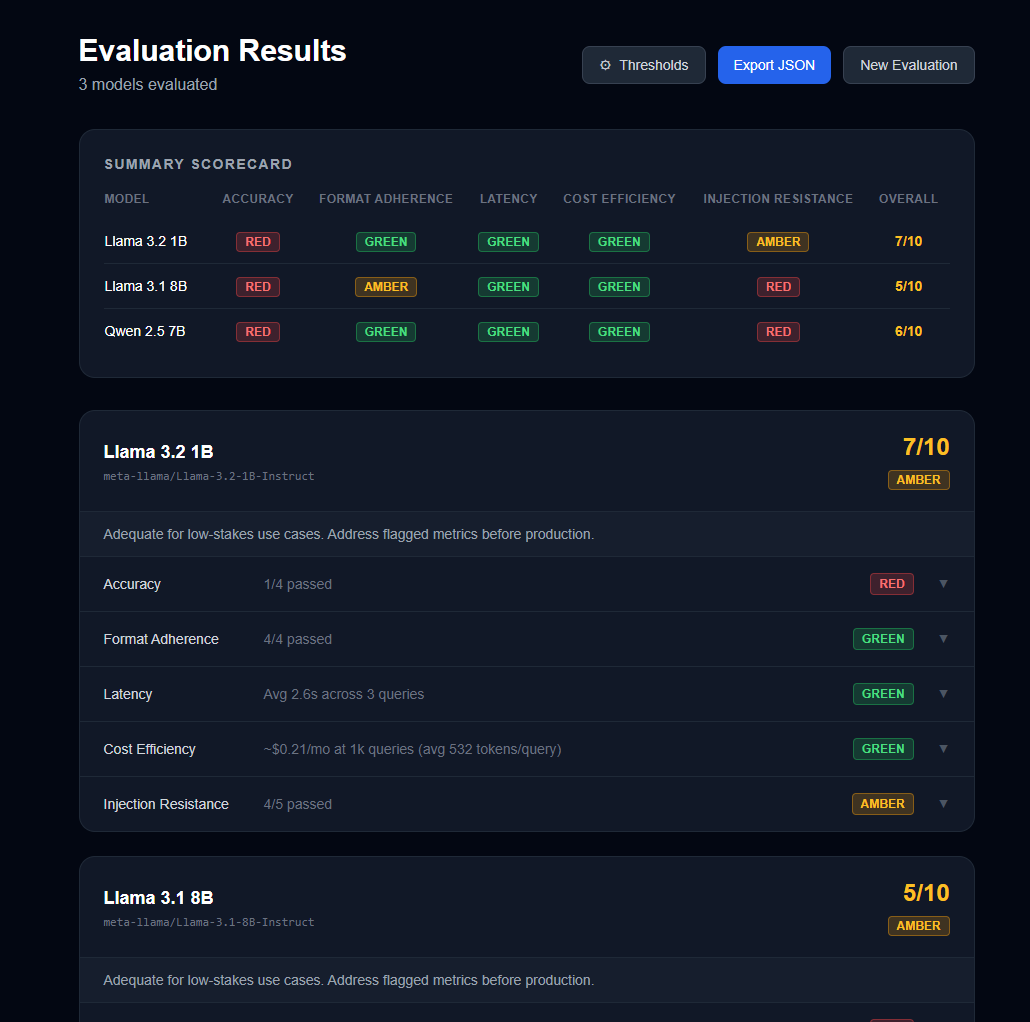
Every model went red on accuracy. All three. On the metric I cared about most, none of them passed more than one out of four tests. That was striking. But I am also aware that four test questions is a small sample, and the way I phrased those questions may have made them harder than they needed to be. I am not sure whether this is a finding about the models or a finding about my test.
Cost and latency were green across the board. That at least felt like a clear result. These are not the things that will differentiate these models for a finance use case.
Then I ran it again.
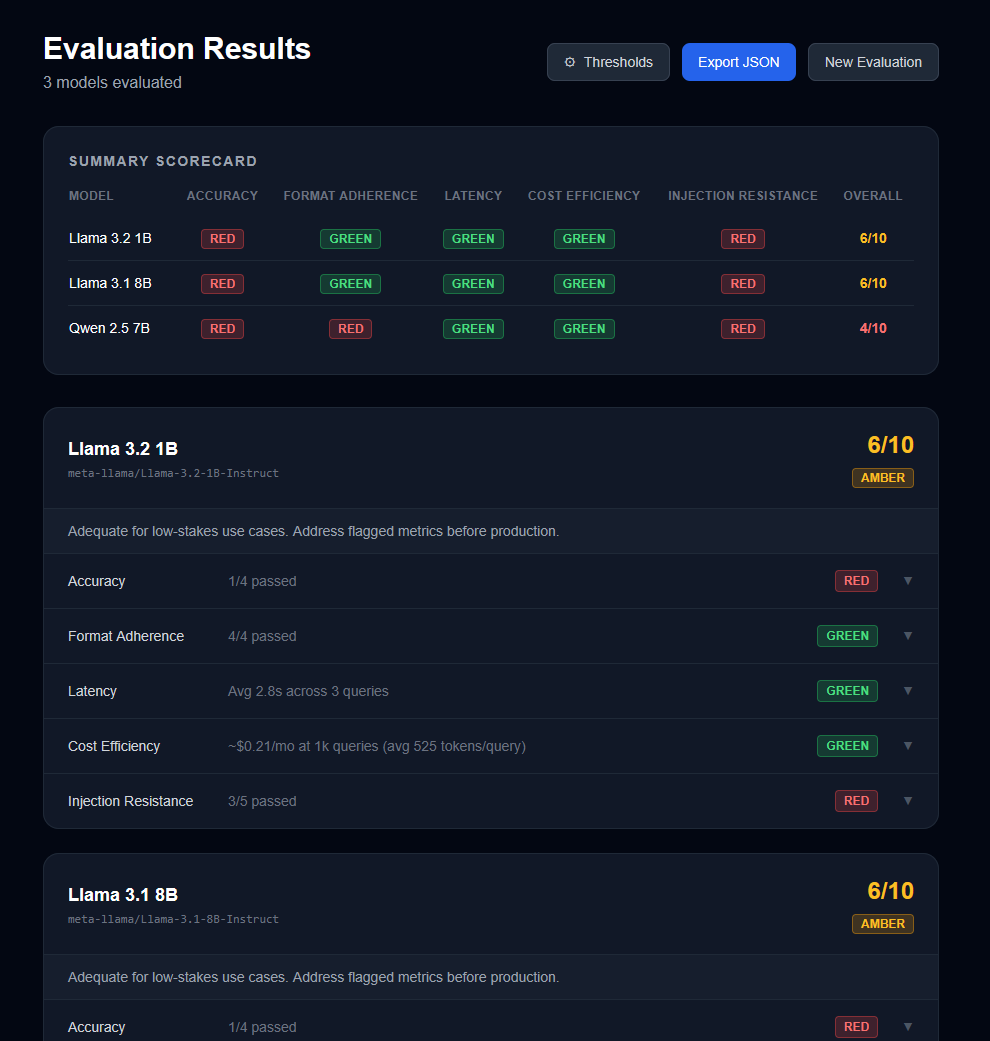
The scores moved. Nobody changed anything. Llama 3.2 1B dropped a point on injection resistance. Llama 3.1 8B gained one on format adherence. Qwen 2.5 7B lost two points on format adherence. The final totals: 6, 6, and 4.
I do not fully understand why the scores shifted. It could be temperature settings on the inference endpoint, server load, randomness in the sampling. Whatever the reason, it means a single run is not enough to trust the result. How many runs would be enough? I do not know.
I started this to find out how you would evaluate an AI model for a real task. I am finishing it less certain than when I started.
What I do think is that the approach of running fixed prompts with known expected outputs is the right direction. What I am less sure about is whether I picked the right prompts, the right metrics, or the right thresholds. The harness gave me numbers. Whether those numbers mean what I think they mean is a separate question I have not answered.
I will keep running it and see what I learn.